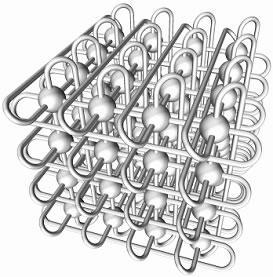
搭建一个3D torus网络
在两个维度上(x,y)有多少个计算节点?假设在水平方向分布N个计算节点,同理在垂直方向也分布N个计算节点。记住,一个理想的torus网络结构,在每个维度上分布相同数量的节点,否则网络会不均衡。你的2D torus网络需要连接NxN个计算节点。
一个3D torus网络,在三个维度各连接NxNxN个节点,假设N=10,那么连接的节点数量将是 10x10x10=1000 节点。这个集群规模不算小。
下面是3D torus拓扑结构图:
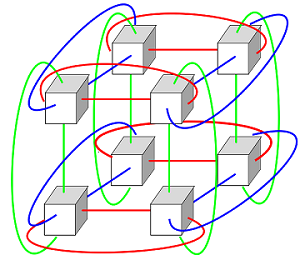

可以看到,3D torus的每个计算节点连接相邻的六个计算节点,位于torus网络边缘的节点同样连接六个相邻的节点,只是它们使用了较长的环绕连接。
在torus上增加维度的的原因在于当连接大量节点时降低延迟。例如,如果你想利用2D torus网络连接N=1000个节点,你需要一个32x32的网格。如果计算机以一种随机的方式交换数据,那么数据包在这样的网格中到达目的地的平均距离要比10×10×10的立方体所能达到的距离大。从网格的左上角开始,最遥远的目的地位于网格的中心。在一个32×32的网格中,你需要向右走大约16步,然后向底部走16步,到达网格的中心——总共32步。
10×10×10立方,达到顶点的中心,您需要沿一个方向走5步到达边缘中心,垂直方向5步,到达一个立方体的中心方面,最后5步到达立方体的中心——这是只有15个步骤,比前面的32步少。更多的步骤意味着更大的延迟,这对并行计算非常有害。这就是大型超级计算机使用5D(如IBM Sequoia)或6D torus的原因。
是否选择使用交换机
在计算机行业有两种方法来构建torus网络。第一种方法是将计算节点放入环面“晶格”中。计算节点的网络适配器内部的电路负责转发流经网络的数据包。不需要专用交换机(这是因为每个网络适配器本身就是一个小交换机)。这样的网络被称为“直接网络”,因为计算节点彼此直接连接,中间没有任何开关。
对于2D(二维)环面网络,您需要一个具有四个端口的网络适配器,将您的节点连接到四个邻居。对于更大的3D网络,有六个邻居,所以你需要一个有六个端口的网络适配器。这种技术的例子有(1)Dolphin公司生产的SCI适配器(这是一种过时的技术)和(2)由Ulrich Bruning教授的课题组设计并由EXTOLL GmbH公司销售的EXTOLL适配器(一种非常新的技术)。
这种方法的一个相当大的好处是,网络的交换元素可以尽可能地靠近要传输数据的来源——CPU。使用EXTOLL技术,网络适配器通过主板上的HTX插槽插入到超传输总线。
但也有缺点。如果您有一个具有6个端口的网络适配器,这意味着6条电缆将连接到每个计算节点。电缆连接器确实占用空间(而且很难让它们更小),所以随着微型化的趋势,六根电缆可能是目前商用硬件的技术极限。
即使是将一根infiniband铜缆连接到每一台普通的机架服务器上,也会产生阻碍气流的布线结构。六根电线太多了。令人欣慰的是,这六根线缆中有两根的传输距离非常短,也就是连接到相邻的计算节点上,就在问题节点的上面和下面,因此它们可以比剩下的四根稍微细一些。或者你可以使用细而昂贵的光缆。
幸运的是,还有另一种构建torus网络的方法,它不需要您将厚厚的线束路由到计算节点。你可以把网络交换机放在环面上,而不是把计算节点放在环面上的“格子”里。普通网络交换机,如带36个端口的InfiniBand交换机。然后,计算节点需要有普通的网络适配器,而包转发将由交换机完成。这种网络被称为“间接”网络,因为计算节点之间不是直接连接,而是通过交换机连接的。
这会产生一定的延迟影响,因为为了得到torus网络,数据包将通过网络适配器和交换机,而在前一个场景中网络适配器也充当了交换机的功能。这同样适用于接收方。因此,如果延迟对您的应用程序很重要,那么您可能希望参考基准测试并选择能够为您提供延迟和成本之间平衡的方法。(如果必须不惜一切代价实现最低的延迟,可以选择胖树结构)
从一个计算节点到一个交换机只需要一条电缆——如果您的计算节点需要更多的带宽,您可以使用更多的线缆。通过这种方式,您可以将18个节点连接到一个36端口交换机。该交换机的其余18个端口将被连接到它的相邻节点——在一个3D环形网络中,连接到其中的6个相邻节点——每一个相邻的交换机上都有一束3根线缆组成的汇聚线缆。
线缆布线图实例
让我们考虑一个由sugon TC4600E-G30服务器组成的计算机集群,并为它设计一个torus网络。计算集群包含96个刀片服务器,每个机箱可以放入8个刀片服务器,刀箱数为96/8=12个刀箱。
在机箱的背面有一个infiniband交换模块,一端连接到infiniband交换机,另一端通过背板连接计算节点,我们选择36口的infiniband交换机,两个刀箱插入交换机占用16个端口,另外16个端口对用户可见,我们将建立一个尺寸为3x4的二维torus网络(因为6x2 torus是不均衡的,甚至可以设计为12x1的torus,但那样做是危险的)
在2D网络中,每个交换机有四个相邻交换机。因此,一个交换机的16个端口将被平均分配——每4个端口分别分配给4个相邻端口——而相邻端口的线缆将以4个端口为一组运行。
一个刀箱需要10U,所以在一个标准的42U机架我们可以放置四个刀箱。因为我们的环面是3×4(或者4×3,没关系),我们可以使用一个机架中的四个刀箱作为环面的一个维度(我们称之为“y”维度,因为机架中的刀箱是垂直堆叠的)。这三个机架提供了另一个维度,我们将其称为“x”,因为机架沿着水平轴彼此邻接。因此,我们将拓扑称为“3×4”。
每个交换机的16个端口将被分为4组:
+y: 1 2 3 4
-y: 5 6 7 8
+x: 9 10 11 12
-x: 13 14 15 16
下面是我们三个机架的图形表示(从后面看)。每个机架容纳4个机箱。每个机箱都有一个交换机。每个交换机的16个端口被分成4组(详细信息见Switch_31)。绘图不按比例(实际42U机架高于显示)

我们从y方向开始,因为它更简单。当我们前进(y增加)时,我们使用来自组“+y”的交换端口。线缆按顺序从组“+y”到下一个开关,再到组“-y”。这是第一个环形:

验证线缆是否按“+y”→“-y”模式运行,例如,从Switch_11上的组“+y”到Switch_12上的组“-y”。特别好的是,这种线缆是完全在机架内。它不会放到头顶的托盘或其他架子上。它在三个机架中都是独立的。我们在其他机柜中上也做了类似的事情:

现在,我们已经完成了y方向布线。让我们从“x”方向开始。困难在于这一次电缆必须从一个机柜连接到另一个机柜,如果你只是从Switch_11拉到Switch_21,机架的门没法关闭,因此我们需要使用头顶的托盘。这需要更长的线缆,特别是位于机柜底部的刀箱。让我们从最上面的交换机开始。

电缆的顺序是黄色、绿色、蓝色。验证布线是否遵循“+x”→“-x”模式(即,黄色线缆从一个交换机上的“+x”到下一个交换机上的“-x”)。
还要注意的是,线缆的示意图显示是垂直向上的,而在真正的气冷装置中,你会选择将线缆与机柜的一侧对齐,这样它们就不会阻碍气流。为此,您可能会选择机柜的右侧,因为左侧可能会被我们的“y”维布线使用(未显示,但仍然在那里)。
下一排交换机的布线类似(之前的布线没有显示,以免使图看起来混乱):

现在您必须以类似的方式连接下面两行交换机,这样就完成了。如果我们试图描述所有的线缆,它将是这样的:


恭喜你!您已经成功地设计了一个包含180个节点的2D环面网络。(如果您希望试验绘图,请下载SVG文件,最好使用Inkscape打开)。
torus网络天生就比胖树便宜。实际上,如果我们试图为12个刀片服务器机架设计一个fat-tree,那么刀箱中的中的交换机将充当边缘交换机,我们将需要为这个fat-tree的第二级单独设置一组核心交换机。因此,胖树结构会更贵。但是,它将提供低延迟和非阻塞带宽。(事实上,如果将计算节点的成本考虑在内,那么fat-tree看起来并没有那么昂贵)。
扩展torus网络架构
如果你从一开始就正确地设计胖树结构的leaf层和spine层,那么胖树就可以很容易地扩展。但是torus呢?我们如何扩展它们?传统的方法是沿着它们的一个维度拉伸它们。
通过上面的例子,我们可以将线缆保持在“y”维度(红色的线,独立于每个机架),并在“x”维度拉伸。我们会根据需要添加尽可能多的机柜,并确保在新旧机柜的边界上,长环绕链接(上图中的蓝色和紫色)不会返回到机架1,而是继续到机架4。最后,从最后一个机柜N,将有一个环绕线缆回到机柜1。
如果从机柜N到机柜1的环绕式链接越来越长,请使用前面幻灯片13中的线缆配置。这样,所有的线缆都会稍微长一点,但没有一根会特别长。
这种传统的环面展开方式会导致网络的不平衡。你觉得一个100×4的环面怎么样?要使这种结构发挥作用,必须满足两个条件:
您的计算代码必须显示通信的局部性。否则,从一个计算节点到另一个计算节点的数据包将需要通过所有中间交换机。这些交换机已经忙于其他任务(这将减少可用带宽),而且跨过有很多这么多交换机将会增加延迟。
另一个条件更难实现:您的作业调度器必须是拓扑感知的,这样它就可以在同一个环面上调度作业的所有进程(实际上,即使对于平衡环面,这个条件也是必需的)。
长话短说,你不可能建造一个100×4的环面,然后希望它能正常工作。你还需要在其他维度上拉伸它。通过上面的例子,你可以做出一个20×20的环面,而不是100×4。(一个尺寸为7x7x8=392的3D环面会更好,但是你需要重新连接所有东西)。
竖直方向是y = 4,现在是20。“y”的尺寸是用红色线缆连接在我们的图形上的。通常,它跨越4个刀箱,这就是为什么它等于4。如果我们想让它等于20,我们需要变成20个刀箱,也就是5个机柜。为了使布线更简单,我们需要在原来的行后面添加另一排机架,然后再添加另一排机架,以此类推,直到有5行。
现在,重新连接红色电缆:从上面的底盘架在前排,它应该去第二行架,通过所有底盘架,遵循第三行,等等,直到所有五行拥抱,然后回到前排。
听起来复杂吗?是的,但对未来的扩张进行适当的规划将使事情变得简单。此外,HPC安装很少会扩展超过两倍,因此在一个维度上进行扩展就足够了。
设计一个3D torus网络架构
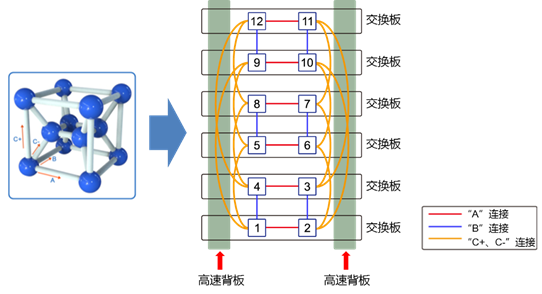
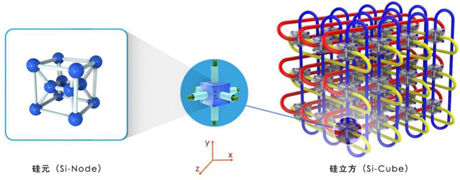
立体环形Torus架构系统整体计算网络分为三层。第一层为全交换网络,计算模块通过全交换网络芯片高速连接,形成一个超节点;第二层为12个超节点按照2x2x3的三维立方体结构进行互联,形成一个硅元;第三层是硅元之间按照X/Y/Z三个方向连接成三维立方体结构,最终形成整个系统,如图所示:
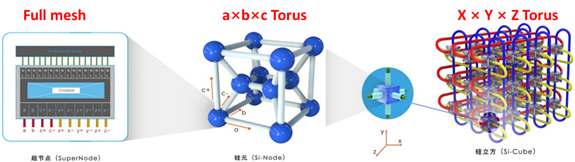
立体环形Torus网络
系统整体计算网络分为三层。第一层为全交换网络,计算节点(Node)通过全交换网络高速连接,形成一个超节点(SuperNode)。如下图所示:
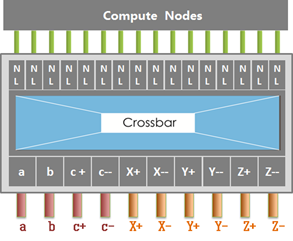
每一个超节点对外有A、B、C+、C-、X+、X-、Y+、Y-、Z+、Z-方向连接其它超节点。12个超节点分别通过A、B、C+、C-网络链路连接起来,每个超节点通过A、B、C+、C-方向连接到4个超节点,形成一个2×2×3的三维立方体结构,即硅元(Si-Node),如下图所示。
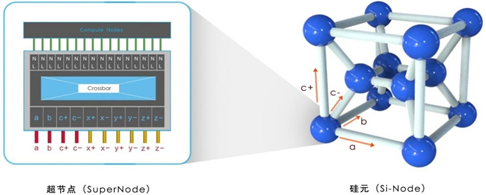
每一个硅元中的超节点都通过X+、X-、Y+、Y-、Z+、Z-六个连接其前、后、左、右、上、下六个硅元中的对应的超级节点,如下图所示,最终形成了整个系统,即硅立方(Si-Cube)。
SuperNode内的全互联可保证局部通信的高带宽和低延迟特性;另一个层面是全系统的多维Torus直接互连结构,保证邻近通信的并发性。
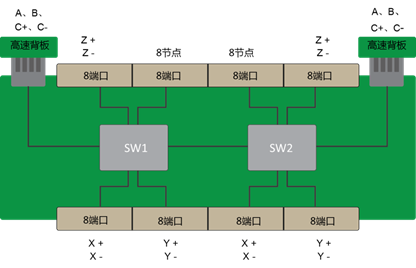
交换机
由于项目规模较大,连线数量多且复杂,对布线、信号稳定性等提出了非常严峻的挑战。为了应对此难点,本项目将采用液冷高性能模块化交换机用于对硅元内部12个超节点之间的连接,通过交换机背板实现3个局部维度构成的双列交叉结构(A、B、C+、C-)的连接,提升系统集成度和信号传输的可靠性。同时,每台硅元交换机对外提供最大192个高速端口用于连接计算节点、最大48个高速端口用于该硅元与其他硅元之间全局维度的3D-Torus连接。