Infiniband胖树结构设计
高性能计算(HPC)通过跨节点的高级并行计算方式,能够更高效地执行计算密集型任务,如气候研究、分子建模、物理模拟、密码分析、地球物理建模、汽车和航空航天设计、金融建模、数据挖掘等。高性能仿真需要高效的计算平台。决定仿真的执行时间取决于许多因素,例如CPU/GPU内核的数量及其利用率、互连性能、效率和可伸缩性。高效的高性能计算系统需要在数千个多处理器节点之间建立高带宽、低延迟的连接,以及高速存储系统。
胖树拓扑
在HPC集群中使用最广泛的拓扑是胖树拓扑。当配置为非阻塞网络时,这种拓扑通常可以在大范围内实现最佳性能。如果可以容忍网络中下联数高于上联数,也可以配置为非全线速网络。胖树集群通常会保证所有的链接使用相同的带宽,并且在大多数情况下,它在所有交换机中使用相同数量的端口。
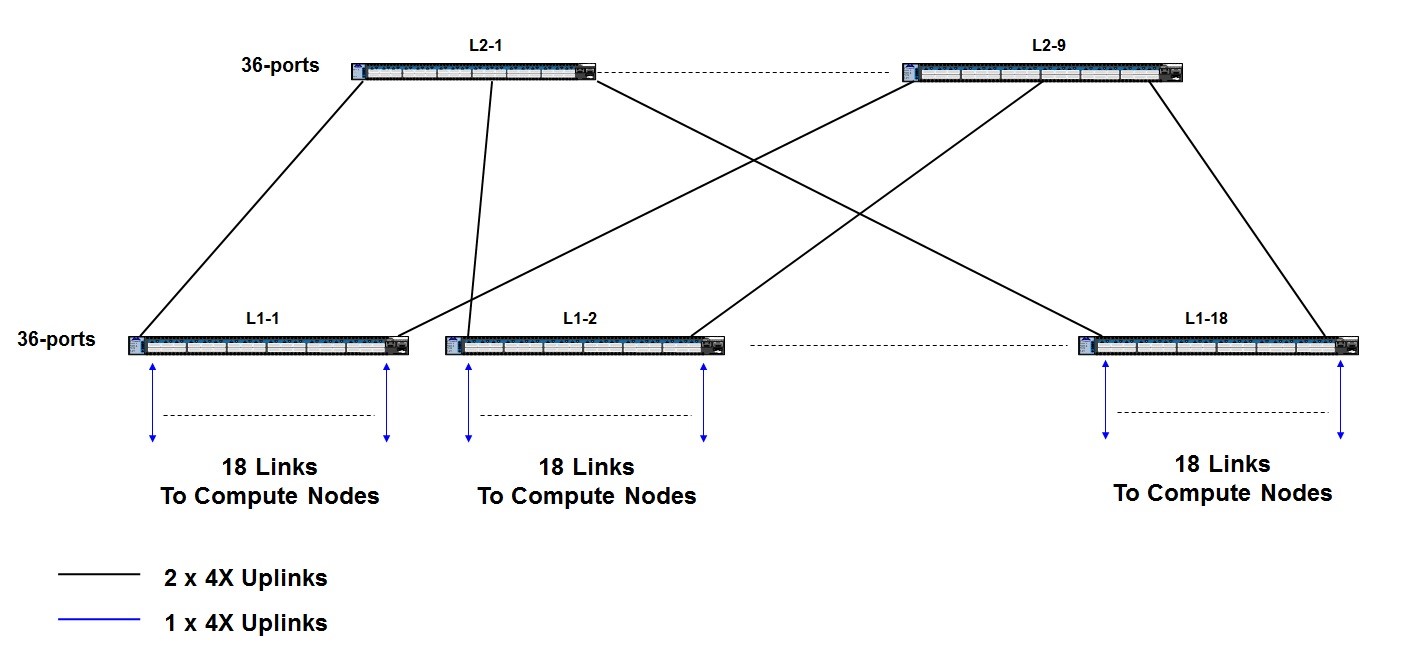
以下是一个324个节点使用36口交换机组成的一个胖树拓扑架构:
核心层交换机包括9个标记为L2的交换机;
每个L1层的交换机下联到主机的端口为18个,总共18个交换机,下联端口总数为324个,此时的网络为全线速;
每个L1层交换机使用2个口和上层每个L2交换机相连;
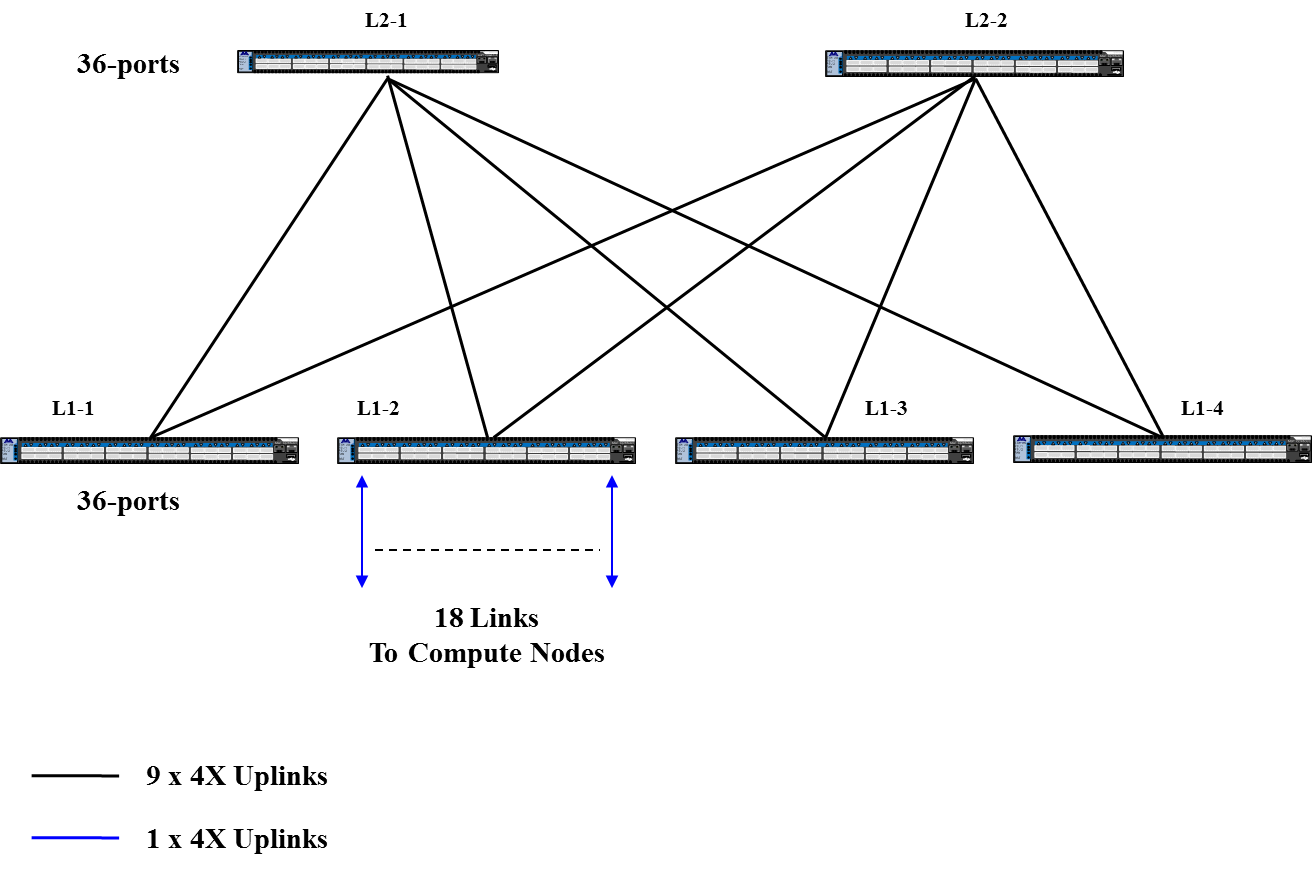
- 72节点胖树
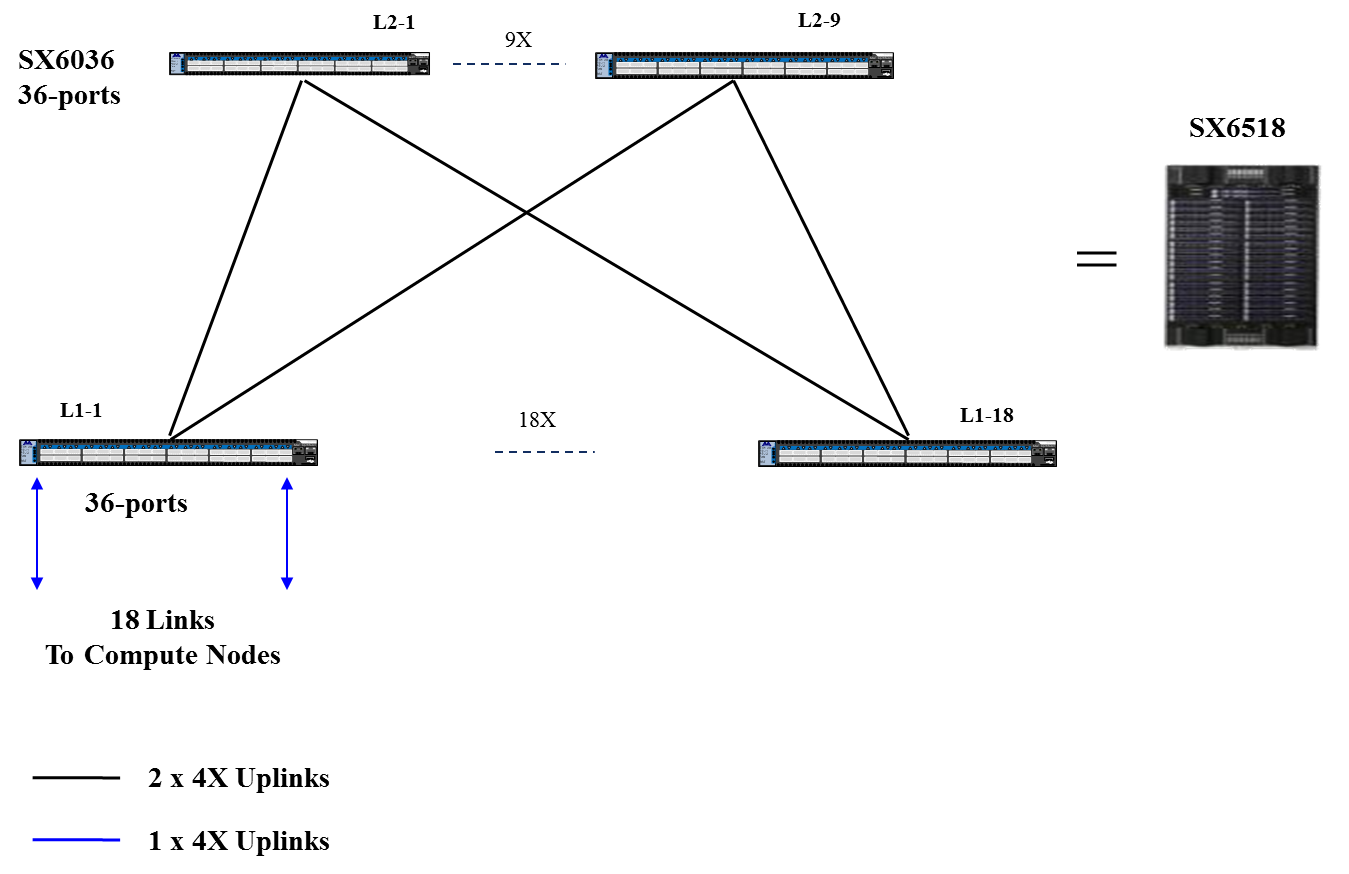
- 324节点胖树
- 1944节点胖树
