搭建一个3D torus网络
在两个维度上(x,y)有多少个计算节点?假设在水平方向分布N个计算节点,同理在垂直方向也分布N个计算节点。记住,一个理想的torus网络结构,在每个维度上分布相同数量的节点,否则网络会不均衡。你的2D torus网络需要连接NxN个计算节点。
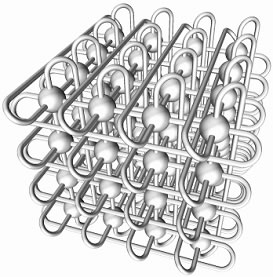
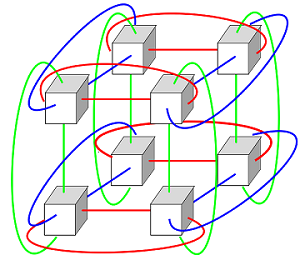
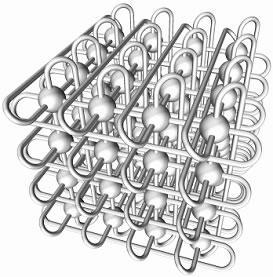
一个3D torus网络,在三个维度各连接NxNxN个节点,假设N=10,那么连接的节点数量将是 10x10x10=1000 节点。这个集群规模不算小。
下面是3D torus拓扑结构图:

探索永无止境
在两个维度上(x,y)有多少个计算节点?假设在水平方向分布N个计算节点,同理在垂直方向也分布N个计算节点。记住,一个理想的torus网络结构,在每个维度上分布相同数量的节点,否则网络会不均衡。你的2D torus网络需要连接NxN个计算节点。
一个3D torus网络,在三个维度各连接NxNxN个节点,假设N=10,那么连接的节点数量将是 10x10x10=1000 节点。这个集群规模不算小。
下面是3D torus拓扑结构图:
介绍Intel Omni-Path架构
英特尔OPA是最新一代英特尔高性能网络交换结构技术。它增加了增强高性能计算性能、可伸缩性和服务质量的新功能。Intel OPA组件包括Intel OP HFI,它提供了网络交换结构、连接大量可伸缩端点的交换机、铜线和光缆,以及一个可识别所有节点、提供集中管理和监控的fabric Manager (FM)。Intel OP HFI是Intel OPA接口卡,提供主机到交换机的连接。Intel OP HFI还可以直接连接到另一个HFI(背对背连接)。
本文主要讨论如何安装Intel OP HFI,配置IP over Fabric,以及如何使用预构建的程序测试Fabric。本例中使用了两个系统,每个系统都配备了Intel®Xeon®E5处理器。两个系统都运行Red Hat Enterprise Linux* 7.2,并配备了通过千兆以太网路由器连接的千兆以太网适配器。
Intel Omni-Path主机网络交换卡
Intel OP HFI是一种标准的PCIe*卡,它与路由器或其他HFI接口相连。Intel OP HFI目前有两种型号:支持100Gbps的PCIe x16和支持56Gbps的PCIe x8。它被设计为低延迟/高带宽,可以配置0到8个虚拟通道外加一个管理通道。MTU大小可以配置为2、4、6、8或10 KB。
下图所示的照片就是OP HFI PCIe x16接口的网卡:

硬件安装
使用两台运行redhat 7.2操作系统,搭载intel E5至强处理器服务器。每台均配备了千兆以太网卡,并通过路由器相连。IP地址分别为10.23.3.27和10.23.3.148。我们将在每台服务器安装Intel OP HFI PCIe x16网卡,并通过Intel OPA线缆进行背对背连接。
首先关闭机器,安装Intel OP HFI网卡,通过Intel OPA 线缆连接网卡,并开机。确认Intel OP HFI上的绿灯正常亮起。这表明Intel OP HFI链状态已被激活。
引言
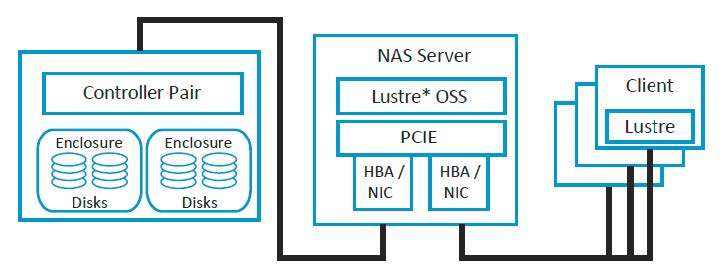
设计一个大规模,高性能存储系统在HPC领域至关重要。本篇文章将逐步介绍搭建此系统所用到的迭代设计方法,将从组件和系统两个方面进行阐述。最后,会给出一个Lustre存储系统的详细的案例,予以佐证。
介绍
一个好的存储系统在各方面的性能都有一个很好的均衡:每一个组件都能发挥其功能,所有的组件协同工作达到一个良好的性能。设计这样一个系统并不是一蹴而就的。一个典型的高性能存储系统包含众多组件,例如,磁盘、存储控制器、IO网卡、存储服务器、存储区域网络交换机以及相关的管理软件。将所有这些组件组合在一起进行调优以期达到一个优越的性能是我们所追求的。
一个经验丰富存储设计者可能会使用一组实用的准则和指南来设计一个存储系统。这些准则通常是基于各自的经验而来。但是,由于存储技术的进步,这些准则可能并不普遍实用,有些甚至已经过时了。例如,有些设计者认为在一个raid组中可以混合不同厂商的制造的硬盘。另一个通用准则说只需要填充硬盘空间的80%,因为控制器可能没有足够的带宽去支持这些添加的容量,因此这些额外的空间可以不需要。但是第二条准则仅仅在特定情况下才实用。
一般来说满足所有需求的存储系统是不存在的。但是,如果我们一开始设计就从一个方面进行着手,再逐渐的融合更多的方面,也许能找到一个在性能,可用性和成本之间的一个平衡点。
在设计初期进行自顶向下需求分析,创建一个完整的视图系统。一旦了解了设计约束,就可以在组件级别确定性能需求。然后就可以一次一个组件的进行构建设计。
存储系统设计的系统级方法
高性能存储系统是大型计算资源的一部分。这样的计算资源通常是由高速网络(HSN)连接到一组磁盘(为数据提供长期存储)的计算机集群(计算节点- CNs)。运行在CNs上的应用程序要么是消费数据(输入),要么是生成数据(输出)。存储这些数据的磁盘通常是分组的,由一个或多个服务器提供服务。各种体系结构以不同的方式连接硬件组件,并通过不同的的软件机制来管理和访问数据。
为这些计算资源设计存储系统的设计人员需要确定存储系统的通用架构,定义该通用存储架构需要的组件,决定这些组件怎样与计算组件和网络组件进行交互。
存储系统初期设计需要列出满足系统需求的列表。该列表可能包含几个多样化的需求,例如:
这将是一个固定的和更加灵活的需求列表,可能还有许多其他的需求。一个固定需求的设计只需要设置满足最小化的需求即可,例如最小带宽。然后,更灵活的需求可以根据固定需求灵活调整,满足整体性能和成本目标。
整个存储系统设计将指定要使用的组件的类型以及它们的连接方式。创建这个设计可能是一个具有挑战性的任务。设计选择由于需要尊重客户或供应商合作伙伴的需求而被限制。
本文首先选择了一个总体设计结构,虽然其他结构也是可行的。如何选择这些基本的设计结构超出了本文的范围,但这里有一些方法可以做到:
在设计完成之前,需要指定每个组件的数量和类型,并确定设计在多大程度上满足需求。当做出设计选择时,一个选择可能会导致一个不满足需求和/或影响其他选择的设计。在这种情况下,需要迭代选择以改进设计。下面的设计方法使用“管道”方法来检查和选择每个组件。
评估组件-管道方法
我们的设计使用“管道”方法来检查每个组件。这种方法按顺序计算组件,当数据从磁盘通过中间的组件流向应用程序时,跟踪数据字节的路径。其他的顺序也是可能的,但是本文仅限于此读取管道
整个管道的性能由其各个组件的性能决定,而系统性能则受到最慢组件的限制,我们需要单独考虑每个组件。
首先,我们检查存储媒介。接下来,将存储控制器与磁盘作为整体一起检查。这两个组件的性能加在一起不会比单独的组件的性能更好,而且由于它们的操作不可避免的效率低下,通常情况下性能会更差。
我们继续这个过程,一次向组合中添加一个组件,直到管道完成。
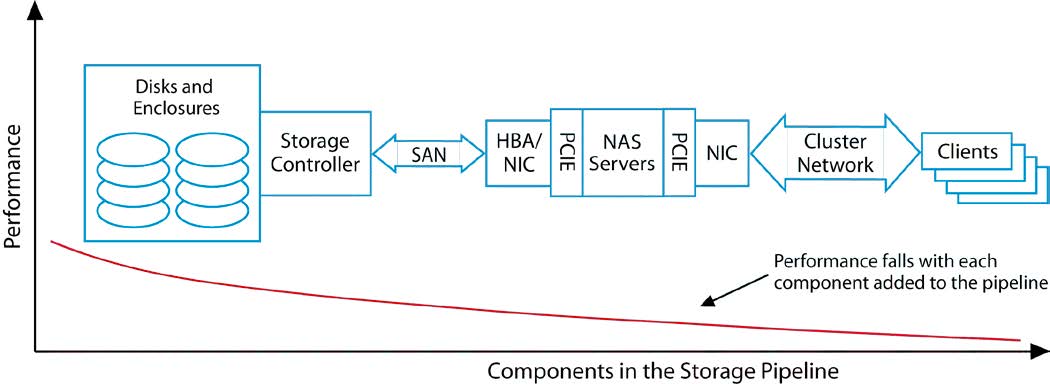
图2根据图1中的顺序把这些组件有序组合起来.从左到右,追踪读管道流。从左至右,该性能曲线代表了每个连续的组件添加到管道后的性能。例如,当添加存储控制器,一些低效率的组件可能会导致两个组件(磁盘和控制器)执行效率略低于单独磁盘的值。曲线显示性能下降(或理想情况下整个曲线保持大致相同),随着额外新的组件被添加。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true